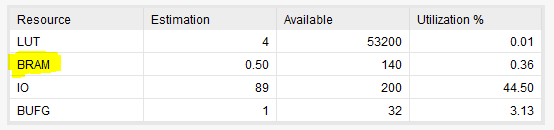
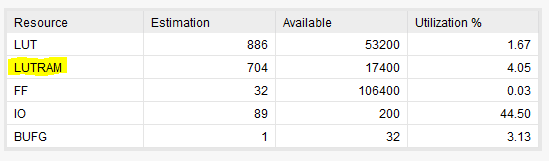
How to determine the maximum operating frequency of the design? It is not straight forward in Vivado compared to ISE. Here is a step by step guide to do this.
Step 1: After finishing the code, run synthesis/implementation. Once it is completed, click on the ‘Constraints Wizard’ link on the SYNTHESIS tab of flow navigator.

A ‘No Constraints File’ window will pop up asking to define the target first. Click on ‘Define Target’.
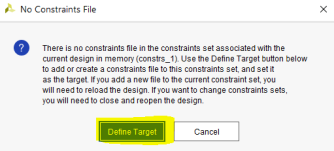
‘Define Constraints and Target window will be opened and click on ‘Create File’ if you don’t already have a constraints file.

Name the file and click OK
Select the created file and click OK

Step 2: Once the file is created, click again on the ‘Constraints Wizard’ option on the SYNTHESIS tab. A window will pop up asking for reloading the design. Click on ‘Reload’.

After reloading, click on the ‘Constraints Wizard’ option again. This time the following ‘Timing Constraints Wizard’ window will open. Click on next.

Next, the clock frequency needs to be defined. Provide the required frequency and click ‘Next’.

The other constraints can be defined if input delays need to be considered. Otherwise, uncheck all the other constraints and click ‘Finish’ at the end.

Before clicking ‘Finish’, make sure you have checked the boxes for the reports you are needed.

Step 3: After finishing, run implementation and that will show the WNS (Worst Negative Slack) in the project summary.

Slack is calculated as ‘required time – arrival time’. WNS shows the spare time we have after meeting the timing requirements. So WNS=6.44ns means it takes only 3.56ns (10ns-6.44ns, where 10ns is the time period for 1 clock cycle for a frequency of 100MHz which we were provided in the constraints file) to complete the execution. To Find the maximum frequency, we have to edit the constraints file for different frequencies until the least possible WNS value we can get which is not negative. Now we checked for operating frequency for 100MHz, and we see that it requires only 3.56 ns for execution.
We can now add a frequency of 300MHz in the constraints file and see what is the WNS. If the WNS is still greater than zero, we can increase the frequency, until no more increment can be done. For example, you set 400MHz in the constraints file and you get a WNS = 0.01ns. When you increase the frequency to 401MHz, the WNS goes negative. That means your maximum operating frequency is 400MHz.
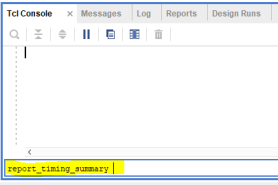
If you need to see an elaborated timing report, just type the tcl command ‘report_timing_summary’ on tcl console and press ‘Enter’.
This will give you an elaborated timing summary with all the clock details.